Rows: 1,732
Columns: 14
$ unitid <dbl> 100654, 100663, 100706, 100724, 100751, 100830, 100858, 1009…
$ name <chr> "Alabama A & M University", "University of Alabama at Birmin…
$ state <chr> "AL", "AL", "AL", "AL", "AL", "AL", "AL", "AL", "AL", "AL", …
$ type <fct> "Public", "Public", "Public", "Public", "Public", "Public", …
$ admrate <dbl> 0.9175, 0.7366, 0.8257, 0.9690, 0.8268, 0.9044, 0.8067, 0.53…
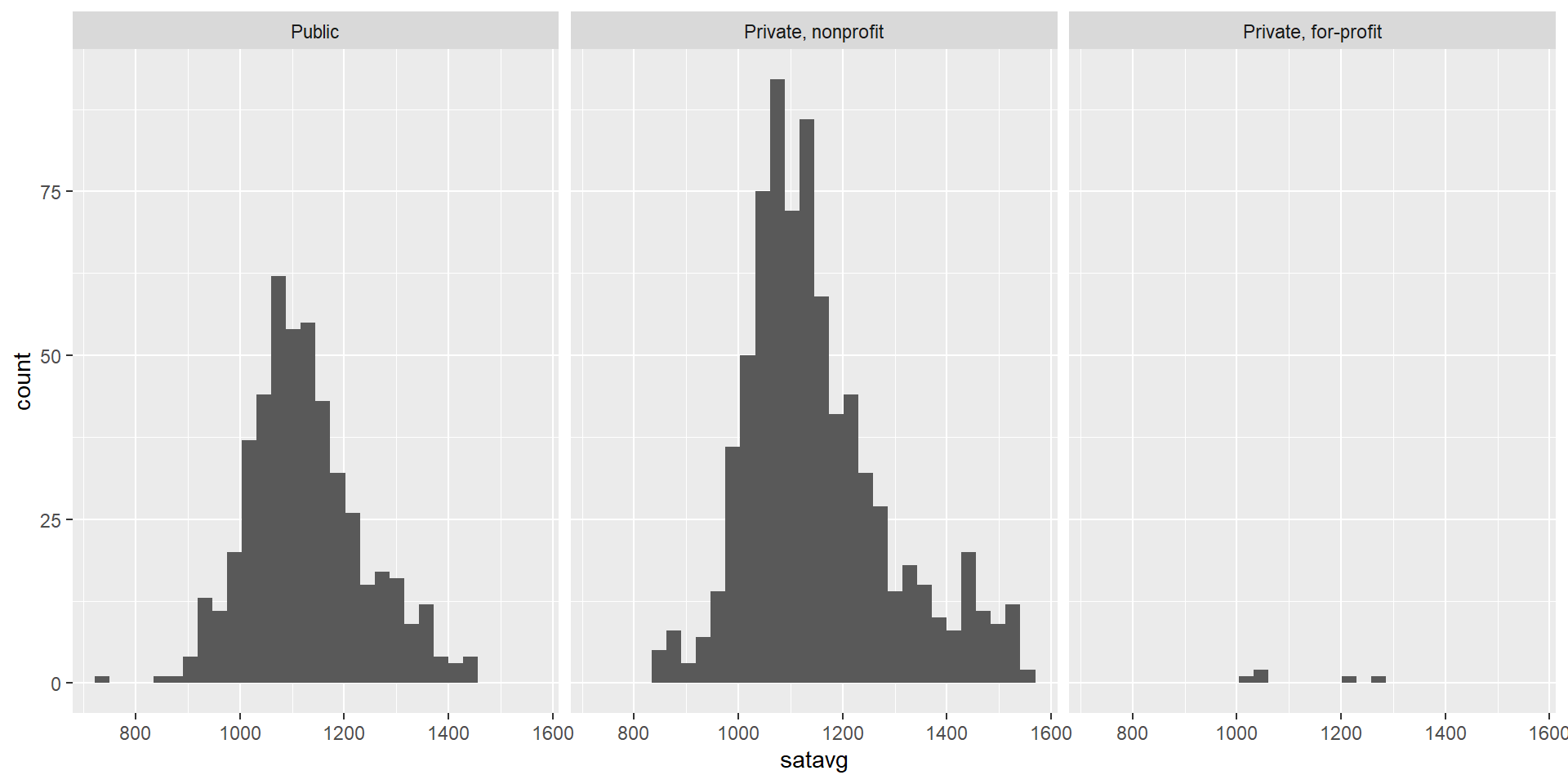
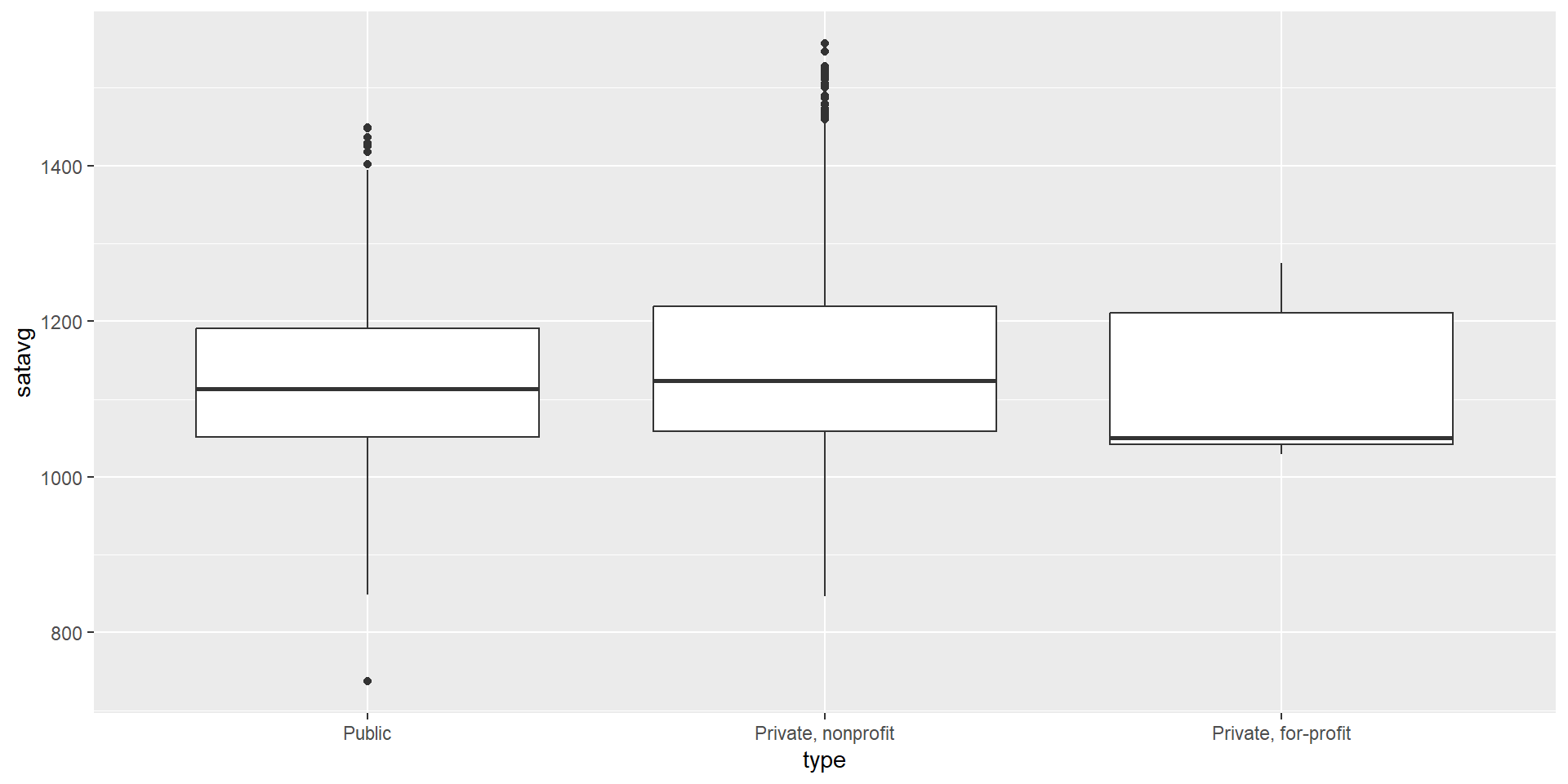
$ satavg <dbl> 939, 1234, 1319, 946, 1261, 1082, 1300, 1230, 1066, NA, 1076…
$ cost <dbl> 23053, 24495, 23917, 21866, 29872, 19849, 31590, 32095, 3431…
$ netcost <dbl> 14990, 16953, 15860, 13650, 22597, 13987, 24104, 22107, 2071…
$ avgfacsal <dbl> 69381, 99441, 87192, 64989, 92619, 71343, 96642, 56646, 5400…
$ pctpell <dbl> 0.7019, 0.3512, 0.2536, 0.7627, 0.1772, 0.4644, 0.1455, 0.23…
$ comprate <dbl> 0.2974, 0.6340, 0.5768, 0.3276, 0.7110, 0.3401, 0.7911, 0.69…
$ firstgen <dbl> 0.3658281, 0.3412237, 0.3101322, 0.3434343, 0.2257127, 0.381…
$ debt <dbl> 15250, 15085, 14000, 17500, 17671, 12000, 17500, 16000, 1425…
$ locale <fct> City, City, City, City, City, City, City, City, City, Suburb…